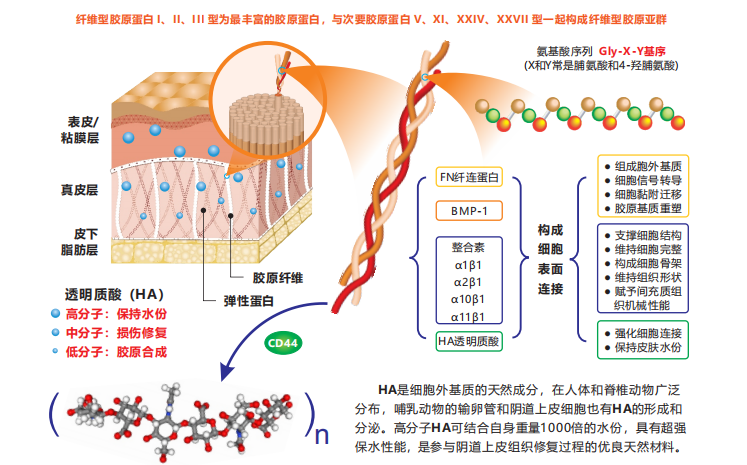
不同类型胶原蛋⽩的组织分布受到限制,具有特定的⽣物学功能,对组织稳态⾄关重要,随着我们对组织纤维化、 组织再生、组织老化和肿瘤发⽣过程的了解越来越多,这些功能正受到越来越多的关注。 I 型胶原蛋⽩是⼈体结缔 组织主要蛋白,由2条相同的 α 1链和1条 α 2链组成,组装成原纤维,构成结缔组织,为其它组织提供形态⽀撑;协调⻣骼、 肌腱、⽪肤和其他组织的形状和功能;在止血、伤口愈合、⾎管生成和生物矿化中发挥作⽤。III型胶原蛋⽩由3条相同 的α链组成,主要形成⽹状纤维,是中空器官(如⼤⾎管,⼦宫和肠道)的结构成分之⼀,也存在于与 I 型胶原相关的许 多其他组织,如⽪肤、软⻣等组织中,III型胶原通常与 I 型和V型等胶原聚合,形成异型原纤维。
在胚胎发育、组织创伤修复等过程中, 在必须承受拉伸的组织器官,例如胎盘,阴道和⼦宫组织中, I 型和 III 型等胶原蛋⽩都需要共同表达。因为, I 型和 III 型等胶原蛋⽩需要⾼度的协同配合,才能维持正常⽣理功能 。 I 型与 III 型等胶原蛋⽩⽐例的变化,可能会改变胶原原纤维的形态,诱发不同组织胶原纤维变异,进⽽引发多种疾病 。
Detect language Afrikaans Albanian Amharic Arabic Armenian Assamese Aymara Azerbaijani Bambara Bashkir Basque Belarusian Bengali Bhojpuri Bosnian Bulgarian Cantonese (Traditional) Catalan Cebuano Chichewa Chinese (Literary) Chinese Simp Chinese Trad Chuvash Corsican Croatian Czech Danish Dari Dhivehi Dogri Dutch Emoji English English United Kingdom Esperanto Estonian Ewe Faroese Fijian Filipino Finnish French French (Canada) Frisian Galician Ganda Georgian German Greek Guarani Gujarati Haitian Creole Hausa Hawaiian Hebrew Hill Mari Hindi Hmong Hungarian Icelandic Igbo Ilocano Indonesian Inuinnaqtun Inuktitut Inuktitut (Latin) Irish Italian Japanese Javanese Kannada Kazakh Kazakh (Latin) Khmer Kinyarwanda Klingon (Latin) Konkani Korean Krio Kurdish (Kurmanji) Kurdish (Sorani) Kyrgyz Lao Latin Latvian Lingala Lithuanian Lower Sorbian Luxembourgish Macedonian Maithili Malagasy Malay Malayalam Maltese Maori Marathi Mari Meiteilon (Manipuri) Mizo Mongolian Mongolian (Traditional) Myanmar (Burmese) Nepali Norwegian Nyanja Odia (Oriya) Oromo Papiamento Pashto Persian Polish Portuguese (Brazil) Portuguese (Portugal) Punjabi Quechua Quertaro Otomi Romanian Rundi Russian Samoan Sanskrit Scots Gaelic Sepedi Serbian Serbian (Cyrillic) Serbian (Latin) Sesotho Setswana Shona Sindhi Sinhala Slovak Slovenian Somali Spanish Sundanese Swahili Swedish Tagalog Tahitian Tajik Tamil Tatar Telugu Thai Tibetan Tigrinya Tongan Tsonga Turkish Turkmen Twi Udmurt Ukrainian Upper Sorbian Urdu Uyghur Uzbek Uzbek (Cyrillic) Vietnamese Welsh Xhosa Yakut Yiddish Yoruba Yucatec Maya Zulu
Chinese Simp English Chinese Trad -------- [ All ] -------- Afrikaans Albanian Amharic Arabic Armenian Assamese Aymara Azerbaijani Bambara Bashkir Basque Belarusian Bengali Bhojpuri Bosnian Bulgarian Cantonese (Traditional) Catalan Cebuano Chichewa Chinese (Literary) Chinese Simp Chinese Trad Chuvash Corsican Croatian Czech Danish Dari Dhivehi Dogri Dutch Emoji English English United Kingdom Esperanto Estonian Ewe Faroese Fijian Filipino Finnish French French (Canada) Frisian Galician Ganda Georgian German Greek Guarani Gujarati Haitian Creole Hausa Hawaiian Hebrew Hill Mari Hindi Hmong Hungarian Icelandic Igbo Ilocano Indonesian Inuinnaqtun Inuktitut Inuktitut (Latin) Irish Italian Japanese Javanese Kannada Kazakh Kazakh (Latin) Khmer Kinyarwanda Klingon (Latin) Konkani Korean Krio Kurdish (Kurmanji) Kurdish (Sorani) Kyrgyz Lao Latin Latvian Lingala Lithuanian Lower Sorbian Luxembourgish Macedonian Maithili Malagasy Malay Malayalam Maltese Maori Marathi Mari Meiteilon (Manipuri) Mizo Mongolian Mongolian (Traditional) Myanmar (Burmese) Nepali Norwegian Nyanja Odia (Oriya) Oromo Papiamento Pashto Persian Polish Portuguese (Brazil) Portuguese (Portugal) Punjabi Quechua Quertaro Otomi Romanian Rundi Russian Samoan Sanskrit Scots Gaelic Sepedi Serbian Serbian (Cyrillic) Serbian (Latin) Sesotho Setswana Shona Sindhi Sinhala Slovak Slovenian Somali Spanish Sundanese Swahili Swedish Tagalog Tahitian Tajik Tamil Tatar Telugu Thai Tibetan Tigrinya Tongan Tsonga Turkish Turkmen Twi Udmurt Ukrainian Upper Sorbian Urdu Uyghur Uzbek Uzbek (Cyrillic) Vietnamese Welsh Xhosa Yakut Yiddish Yoruba Yucatec Maya Zulu
Text-to-speech function is limited to 200 characters